
티스토리 뷰
Improving RetinaNet for CT Lesion Detection with Dense Masks from Weak RECIST Labels
Arc Lab. 2019. 9. 3. 21:08[업데이트 2019.09.03 21:03]
1. 논문
Improving RetinaNet for CT Lesion Detection with Dense Masks from Weak RECIST Labels
Martin Zlocha, Qi Dou, Ben Glocker (Submitted on 5 Jun 2019)
Comments: Accepted at MICCAI 2019
Subjects: Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
Cite as: arXiv:1906.02283 [eess.IV] (or arXiv:1906.02283v1 [eess.IV] for this version)
https://arxiv.org/abs/1906.02283
-GitHub: https://github.com/martinzlocha/anchor-optimization
2. 요약
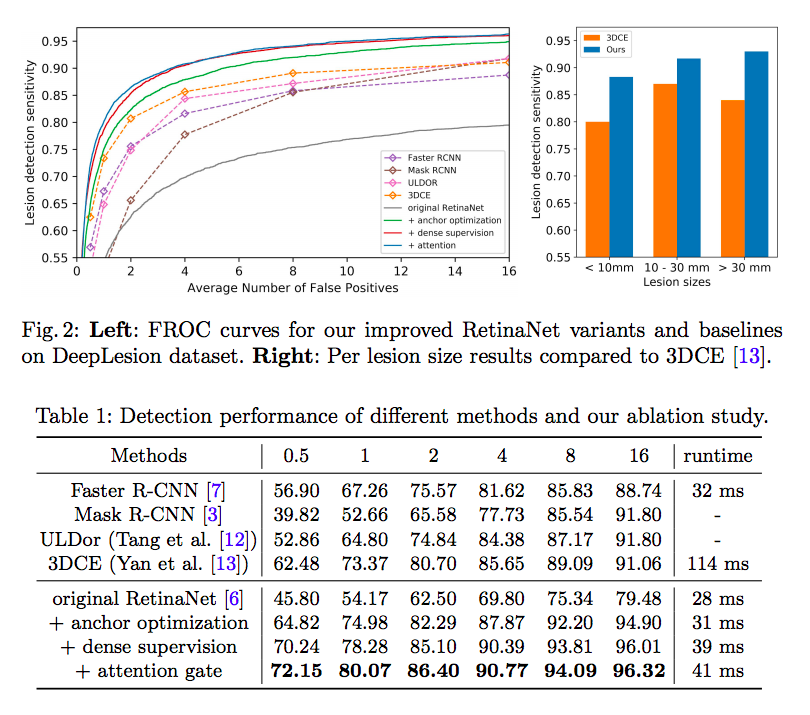
- We propose a highly accurate and efficient one-stage lesion detector, by re-designing a RetinaNet to meet the particular challenges in medical imaging.
1) Anchor Optimization
- The anchor configuration is crucial for the detector, and we find the default anchor sizes (32, 64, 128, 256 and 512), aspect ratios (1:2, 1:1 and 2:1) and scales (2 0 3 , 2 1 3 and 2 2 3 ) turn out to be ineffective for detecting lesions of small size and large ratios.
- We employ a differential evolution search algorithm [11] to optimize ratios and scales of anchors on the validation set. This algorithm iteratively improves a population of candidate solutions with regard to an objective function.
- New solutions are created by combining existing ones. We aim to find the best anchor settings for 3 scales and 5 ratios. The objective is to maximise the overlap between the lesion bounding-box and the best anchor on the validation dataset. We fix one ratio as 1:1, and define other ratios as reciprocal pairs (i.e., if one ratio is 1 : γ then another is γ : 1).
- Thus, we need to optimise only five variables, i.e, two ratio pairs and three scales. When initialising the population of candidate solutions, all scales are bounded to a range of [0.4, 1.6] and the two ratios are respectively bounded in [1, 2] and [2, 4]. We obtain optimal scales as 0.425, 0.540 and 0.680, and ratios of 3.27:1, 1.78:1, 1:1, 1:1.78, 1:3.27, which fits objects of small size and large ratios. Anchor sizes remain as (32, 64, 128, 256 and 512). These optimised configurations are then used for training the detector.
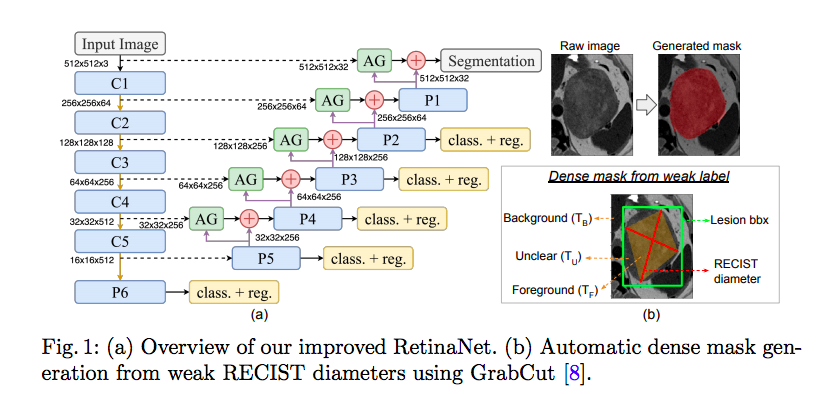
2) Attention Gate Dense Mask Supervision from Weak RECIST Labels
- The anchor co. To leverage this highly valuable information, we automatically generate dense lesion masks from
RECIST labels (provided in the DeepLesion dataset) using GrabCut [8]. We initialize a trimap into background (TB), foreground (TF ) and unclear (TU ) pixels. A segmentation mask is generated based on iterative graph-cuts.
- To exploit these generated dense labels, we add two more upsampling layers (connecting to P2 and P1) and a segmentation prediction layer to the detector. Skip connections are employed by fusing features obtained from C1 (via a 1 × 1 convolution) and input (via two 3 × 3 convolutions), as shown in Fig. 1(a). To retain sufficient resolution of feature maps for small lesions, we shift the
sub-network operation (i.e., classification and regression) to pyramid levels of
P2-P6 from P3-P7.
3) Attention Mechanism for Gated Feature Fusion
- A recent attention gate (AG) model proposed by Schlemper et al. [9] learns to
focus on target structures by producing an attention map.
- According to this work, this may be beneficial for small, varying structures.
We explore AGs to filter feature responses propagated through skip connections and use features
upsampled from coarser scale as the gating signal.
- The AG module only uses 1×1 convolutions and produces a single attention map, which makes it computationally light-weight. The output of AG is the element-wise multiplication of the attention map and the feature map from the skip connection.
- Total
- Today
- Yesterday
- project
- #TensorFlow
- Meow
- Game Engine
- Memorize
- #ELK Stack
- docker
- SSM
- 도커
- ILoop Engine
- ate
- sentence test
- 2D Game
- Ragdoll
- belief
- English
- Mask R-CNN
- Jekyll and Hyde
- aws #cloudfront
- Sea Bottom
- #ApacheSpark
- OST
- #REST API
- Worry
- some time ago
- Library
- Badge
- GOD
- Physical Simulation
- #ApacheZeppelin
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |