
 [Zeppelin/Spark] Get Started
[Zeppelin/Spark] Get Started
[업데이트 2020.05.27 17:13] 빅데이터 분석 및 시각화를 위해 Zeppelin과 Spark를 연동하여 사용하는 것에 대해 간단히 정리하였습니다. - https://zeppelin.apache.org/docs/latest/quickstart/install.html - http://zeppelin.apache.org/download.html Zeppelin docker image를 사용하여 실행해보도록 하겠습니다. 아래와 같이 8080포트로 실행합니다. docker run -p 8080:8080 --rm --name zeppelin apache/zeppelin:0.9.0 아래와 같이 docker volume 옵션을 사용하여 로그 및 노트북이 저장 가능합니다. docker run -p 8080:8..
 [Apache Spark] Windows에서 Standalone Cluster 실행
[Apache Spark] Windows에서 Standalone Cluster 실행
[업데이트 2017.03.21 10:42] Windows에서 Standalone Cluster 실행하는 방법에 대한 포스팅입니다. 1. Master Node 실행C:\spark-2.1.0\bin>spark-class.cmd org.apache.spark.deploy.master.Master 다음과 같이 master node에 대한 web UI(기본적으로 http://localhost:8080으로 실행됩니다)를 접속하여 정상적으로 master node가 실행 되었는지 확인 할 수 있습니다. 또는 다음과 같이 특정 IP/Port를 지정하여 실행 할 수 있습니다. C:\spark-2.1.0\bin>spark-class.cmd org.apache.spark.deploy.master.Master -i 192.16..
[업데이트 2017.03.17 15:51] Zeppelin Spark Interpreter(Scala/Python)를 이용한 Oracle DB 연동 테스트 입니다. 테스트 해본 결과 확실히 Scala가 더 빠른 응답속도를 보여주었습니다. Spark에서 Scala에 더 최적화가 되어 있음을 확인 할 수 있습니다. * 참고: http://bcho.tistory.com/1031 ** 추가 업데이트: 원문 도표를 보면 core 개수가 적을 때는 Scala가 빠르지만, core 개수가 많아지면 Python도 동등한 수준임을 알 수 있습니다. 제가 테스트한 DB table query 기준으로 퍼포먼스에 있어서 상당한 차이가 있었습니다. 아래는 제가 테스트 했을 때 확인한 응답 속도입니다. [응답 속도] Scala ..
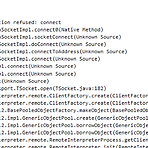 [Apache Zeppelin] Spark Interpreter 이슈 해결
[Apache Zeppelin] Spark Interpreter 이슈 해결
[업데이트 2017.03.17 13:28] Windows 환경에서 Zeppelin Release 0.7.0 버전 기준으로 Apache Zeppelin-Spark Interpreter 연동시 아래와 같은 에러를 접하게 되었습니다. 구글링을 하면서 찾다보니 문제 해결 방법에 대한 힌트를 아래의 사이트를 통해 얻게 되었습니다. * 참고: https://issues.apache.org/jira/browse/ZEPPELIN-1584 Zeppelin에서 Spark Interprester를 실행하는데, 이때 Spark Interpreter 실행시 넘겨주는 파라메터 처리 이슈로 Spark Interpreter가 정상적으로 실행이 안되어 문제가 발생한 것으로 보입니다. 아래는 로그 내용입니다. 결국 connect tim..
 [Apache Zeppelin] 설치 및 인증 기능 설정
[Apache Zeppelin] 설치 및 인증 기능 설정
[업데이트 2017.03.15 16:46] Apache Zeppelin의 경우 초보자도 사용하기 쉽게 가이드가 구성되어 있었습니다. 아래의 주소로 접속 후, 먼저 Zeppelin 최신 버전을 받습니다. 2017.03.15 기준 0.7이 최신입니다. Windows 기준으로 설치 및 실행에 대해 정리하였습니다. * 참고: https://zeppelin.apache.org/ 아래의 다운로드 페이지로 이동 후 , Binary package with all interpreters를 다운로드합니다. * 참고: https://zeppelin.apache.org/download.html 다운로드 후, tgz 압축 파일을 압축 해제 후, 적절한 위치에 7zip으로 한번 더 압축을 해제 합니다. 아래의 7.0 버전의 문서..
[업데이트 2017.03.13 20:16] Spark에서 Oracle DB 접근에 대한 포스팅입니다. Windows 환경에서 Python을 가지고 테스트를 해보았습니다. 1. Oracle DB JDBC jar 파일 다운로드 및 spark-defaults.conf 설정하기 다운로드 받은 Oracle DB JDBC jar파일을 적절한 위치에 복사한 후, Spark home/conf 폴더의 spark-defaults.conf의 spark.driver.extraClassPath에 해당 jar 파일 경로를 추가 합니다.spark.driver.extraClassPath C:\\oracle-jdbc-driver-11g\\ojdbc6.jar 2. Oracle JDBC test .py 파일 작성 및 실행 다음과 같이 O..
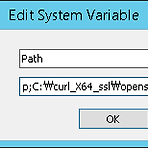 [Apache Spark] Windows 환경에서 설치시 이슈 해결 방법
[Apache Spark] Windows 환경에서 설치시 이슈 해결 방법
[업데이트 2017.03.13 17:20] Windows에서 Spark 설치를 위해 많은 부분을 해맸었는데, 아래의 링크를 통해 설치를 마무리 할 수 있었습니다. 가장 중요한 부분은 Windows 환경 변수 설정 부분으로 이 부분만 잘 하면 Spark가 Windows 환경에서도 정상적으로 동작하게 됩니다. 추가로 아래의 포스팅에는 Python에 대한 설정이 없는데, 다음과 같이 Path에 C:\Python27와 같이 home directory를 설정하면 됩니다. * 참고: https://hernandezpaul.wordpress.com/2016/01/24/apache-spark-installation-on-windows-10/
[업데이트 2017.02.14 11:15] Elasticsearch로 입력하는 데이터의 field가 많고, 특정 field는 number로 변환이 되어야 하는 경우에 _default_ mapping에 numeric_detection를 true로 설정하여 사용합니다. 그러나 version 체계(예: 1.00)를 명시하는 field의 경우 Elasticsearch에 입력시 잘못된 데이터 타입 변환으로 아래와 같이 오류가 발생할 때가 있습니다. :response=> { "index"=> {"_index"=>"logstash-data-2016.01", "_type"=>"data", "_id"=>"14173638", "status"=>400, "error"=> {"type"=>"illegal_argument_ex..
[업데이트 2017.02.10 15:39] 1. JAVA_HOME 오류 HADOOP_HOME/etc/hadoop/hadoop-env.cmd 수정.(Program Files space때문에 오류 발생) symbolic link로 지정함.mklink /D \java_home "C:\Program Files\Java\jre1.8.0_111" set JAVA_HOME=\java_home * 참고: http://stackoverflow.com/questions/26990243/hadoop-installation-on-windows 2. util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Coul..
 [ELK Stack] Elasticsearch text field에서 특정 문자열 개수 구하기(Document Count)
[ELK Stack] Elasticsearch text field에서 특정 문자열 개수 구하기(Document Count)
[업데이트 2017.01.06 17:55] 예를 들어 다음과 같은 시나리오가 있을 때, 특정 text field에 포함된 문자열의 개수를 counting 하는 방법을 찾아보았습니다. 현재 찾은 방법은 text field에 동일한 문자열이 여러개 있더라도 document당 1개로 count를 합니다. - index: logstash-app-name - type: data1 - field: AppNameList * field의 analyzed 속성이 true여야 full text 검색이 가능합니다. - field text : "word, test, word, rundll32, autocad, autocad" 먼저 Logstash 등을 통해 Elasticsearch에 데이터를 insert할 때, 해당 fiel..
- Total
- Today
- Yesterday
- Jekyll and Hyde
- GOD
- 도커
- Memorize
- Meow
- Library
- sentence test
- Ragdoll
- project
- #ApacheZeppelin
- Mask R-CNN
- SSM
- English
- #REST API
- ate
- Sea Bottom
- #TensorFlow
- ILoop Engine
- OST
- 2D Game
- Badge
- some time ago
- aws #cloudfront
- docker
- Worry
- Physical Simulation
- #ApacheSpark
- belief
- Game Engine
- #ELK Stack
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |